
机器学习的七个最佳实践
时间: 2020-03-15来源: Salesforce知识

Netflix著名的算法挑战赛,向预测用户对电影评分的较佳算法颁发了100万美元的奖金。但是您知道获胜算法从未实现到功能模型中吗?
Netflix报道说,该算法取得的成果似乎并不能证明将其引入生产环境所需的工程工作是合理的。这是机器学习的一大问题。
在您的公司,您可以创建任何人都见过的非常优雅的机器学习模型,即使您从不部署和操作它也没有关系。但这并非易事,这就是为什么我们向您展示机器学习的七个最佳实践的原因。
本文内容整理于对近期参与数据和分析峰会的数据挖掘和分析产品管理总监Charlie Berger的采访。
将模型付诸实践的时间可能比您想象的要长。TDWI的一份报告发现,28%的受访者花了三到五个月的时间才将他们的模型投入使用。几乎有15%的人需要超过9个月的时间。
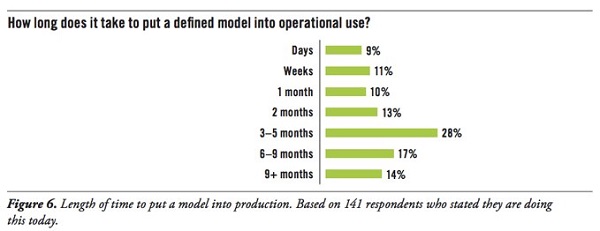
那么,您如何做才能开始更快地部署机器学习呢?在这里列出了我们的建议:
1.别忘了开始行动
在以下几点中,我们将为您提供一系列不同的方法,以确保以更佳方式使用您的机器学习模型。但是我们从更重要的一点开始。
事实是,在机器学习的这个阶段,许多人根本就没有开始。发生这种情况的原因有很多。技术很复杂,也许买不到,或者人们只是难以把每件事都做好。所以这是Charlie的建议:“即使您知道不得不每月重建一次模型,也要开始使用。因为你从中学到的东西是无价的。”
2.从业务问题陈述开始,建立正确的成功指标
从业务问题入手是常见的机器学习更佳实践。但它之所以常见,恰恰是因为它是如此重要,但许多人却不把它放在首位。
想一想这句话:“如果我有一个小时来解决一个问题,我会花55分钟思考这个问题,5分钟思考解决方案。”
现在,请确保将其应用到机器学习场景中。下面,我们列出了定义不明确的问题陈述以及以更具体的方式定义问题的方式示例。

想想你对盈利能力的定义是什么。例如,我们近期与一家全国性的快餐连锁店进行了洽谈,他们希望增加软饮料的销量。在这种情况下,我们必须仔细考虑定义交易的含义。该交易是单人餐,还是一家人的六人餐?这很重要,因为它会影响您显示结果的方式。您必须考虑如何解决该问题并将其付诸实施。
除了建立成功指标之外,您还需要建立正确的指标。指标将帮助您建立进度,但是改进指标真的能改善终端用户体验吗?例如,您的传统度量指标可能包含精度和平方误差。但是,如果您试图创建一个衡量航空公司价格优化的模型,那么您的每次购买成本和总体购买成本没有增加就没关系。
3.不要移动数据–移动算法
预测建模的致命弱点是这是一个两步过程。首先,您通常基于样本数据构建模型,这些数据的数量从数百到数百万不等。然后,一旦建立了预测模型,数据科学家就必须应用它。然而,这些数据中的大部分都驻留在某个数据库中。
假设您要获得美国所有人的数据。美国有3亿6千万人口,这些数据存放在哪里?可能在某个地方的数据库中。
您的预测模型位于何处?
通常的情况是人们会把他们所有的数据从数据库中取出来,这样他们就可以用他们的模型来运行方程。然后,他们必须将结果重新导入数据库以进行预测。这个过程需要花费数小时,甚至数天的时间,从而降低了您所构建的模型的效率。
但是,从数据库中扩展方程具有显著的优势。通过数据库内核运行方程式需要花费几秒钟,而导出数据需要花费数小时。然后,数据库也可以完成所有数学运算并在数据库中构建它。对于数据科学家和数据库管理员来说,这意味着一个世界。
通过将数据保留在数据库和Hadoop或对象存储中,您可以在数据库中构建模型和评分,并使用具有数据并行调用的R包。这样,您就可以消除数据重复并分离分析服务器(不移动数据),并且可以在数小时内对模型进行评分,嵌入数据准备,构建模型和准备数据。
4.整合正确的数据
正如James Taylor和Neil Raden在Smart Enough System一书中所写,对您拥有的所有东西进行分类并确定哪些数据是重要的是处理问题的错误方法。正确的方法是从解决方案开始,明确定义问题,并绘制出构成调查和模型所需的数据。
然后,是时候与其他团队合作了。
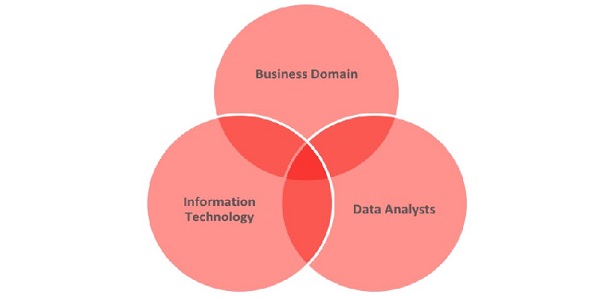
这是您可能开始陷入困境的地方。因此,我们将参考第1点,即“别忘了真正开始行动。”同时,整合正确的数据对您的成功非常重要。
为使您找出用于填充调查和模型的正确数据,您需要与业务领域,信息技术和数据分析师这三个主要领域的人员进行交谈。
业务领域-这些都是了解业务的人:
• 市场营销和销售
• 客户服务
• 运营
信息技术-有权访问数据的人:
• 数据库管理员
数据分析师-了解业务的人:
• 统计员
• 数据挖掘者
• 数据科学家
您需要积极参与。没有它,您将收到类似的评论:
• 这些线索都不好
• 数据过时了
• 该模型不够精确
• 您为什么不使用这些数据?
5.创建新的派生变量
您可能会想,我已经掌握了所有这些数据。我还需要什么?
但是创建新的派生变量可以帮助您获得更多有见地的信息。例如,您可能正在尝试预测第二天报纸和杂志的销量。以下是你已经知道的信息:
• 实体店或售货亭
• 卖彩票?
• 本次抽奖金额
当然,您可以根据该信息做出猜测。但是,如果您能够首先比较当前彩票奖赏金额与典型奖赏金额,然后将该派生变量与您已经拥有的变量进行比较,您将得到一个更准确的答案。
6.在发布之前考虑问题并进行测试
理想情况下,一开始您应该能够使用两个或多个模型进行A / B测试。你不仅知道你怎么做是对的,而且当你知道你做的是对的时候,你会更有信心。
但是,除了进行全面测试之外,当事情出错时,你也应该有一个适当的计划。例如,您的指标开始下降。有几件事会涉及到这一点。您将需要某种形式的警报,以确保可以尽快调查此事。当副总裁进入您的办公室想知道发生了什么时,您将不得不向可能没有工程背景的人解释发生了什么。
当然,在发布之前,您需要计划一些问题。遵守法规是其中之一。例如,假设你申请汽车贷款却被拒绝了。根据GDPR的新规定,您有权知道原因。当然,机器学习的问题之一是它看起来像一个黑匣子,甚至工程师/数据科学家也无法说出为什么做出某些决定。但是,某些公司将通过确保您的算法能提供预测细节来为您提供帮助。
7.在企业范围内部署和自动化
部署后,不要局限于数据分析师或数据科学家。
我们的意思是,始终要思考如何在整个企业中发布预测和可行的见解。重要的是了解数据在哪里以及何时可用,才使数据有价值;而不是它存在的事实。您不想成为坐在象牙塔中的人,发布一些零星的见解。您想要无处不在,每个人都需要更多的见解-简而言之,你想要确保自己是不可或缺的,是极其有价值的。
鉴于我们所有人都只有这么多时间,因此如果可以自动化的话,这是较简单的,创建仪表板。将这些见解纳入企业应用程序。看看您是否可以成为客户接触点的一部分,就像一台自动提款机能识别出客户定期在每个周五晚上提取100美元,在每个发薪日之后提取500美元。
结论
这是机器学习更佳实践的核心要素。你需要良好的数据,否则将一事无成。您需要将其放在数据库或对象存储之类的地方。您需要深入了解数据以及知道如何处理数据,无论是创建新的派生变量还是使用它们的正确算法。然后,您需要实际使用它们从中获得深入的见解,通过信息传播它们。
其中较困难的部分是启动您的机器学习项目。我们希望通过这篇文章可以帮助您迈向成功。
编译自:7 Machine Learning Best Practices 作者: Sherry Tiao (ORACLE)