
Salesforce AI新研究,翻译中的情境化词向量
时间: 2017-08-08来源: 怡海软件

Salesforce Einstein发布以来究竟做了哪些事情,做了哪些高科技含量的事情,下面我们就来一起看一看Salesforce Einstein 在自然语言处理领域的新研究吧。
Salesforce 在去年成立新部门 Salesforce Research,专门处理关于深度学习、自然语言处理,和计算机视觉辨识技术的研究,协助用在 Salesforce 的产品线上。其人工智能服务爱因斯坦AI (Einstein AI),将与他们既有的云端服务结合,提供更好的服务。近期,他们发布了新的自然语言处理成果,我们一起来看看。
现如今,自然语言处理(NLP)找到一个很好的实现方法,通过对单个单词的理解以植入新的神经网络,但是该领域还没有找到一种方法可以初始化新网络,理解这些单词与其他单词之间的关系。我们的研究打算利用已经学会了如何使文本情境化的网络,从而使新的神经网络能够学习理解自然语言的其他部分。
对于NLP中的大多数问题来说,理解情境至关重要。翻译模型需要了解英语句子中的单词是如何协同工作的,从而生成德语翻译。摘要模型需要通晓上下文,从而知道哪些词是更重要的。执行情绪分析的模型需要了解如何能够掌握那些改变他人表达情绪的关键词。问答模型依赖于对一个问题中的词语如何改变一个文档中词语重要性的理解。由于这些模型中的每一个都需要理解情境是如何影响单词的含义的,因此每个模型都可以通过与已经学习如何情境化单词的模型相结合来获益。
一条通往NLP Imagenet-CNN的路径
在找寻可重复使用的表征方面,显然计算机视觉已经比NLP取得了更大的成功。在大图像分类数据集(ImageNet)上训练的深度卷积神经网络(CNN)经常用作其他模型中的组件。为了更好地对图像进行分类,CNN通过逐渐构建像素是如何与其他像素相关的更为复杂的理解,来学习图像的表征。诸如图像标注、面部识别和目标检测等模型处理任务都可以从这些表征开始,而不需要从头开始。NLP应该能够做一些和单词及其语境类似的事情。
我们可以教一个神经网络如何在情境中理解单词。首先,教它如何将英语翻译成德语;然后,我们将以一种方式来展示我们可以重复使用这个网络,即计算机视觉中在ImageNet上进行训练的CNN的重用。我们通过将网络的输出,即情境向量(context vectors (CoVe))作为学习其他NLP任务的新网络的输入来实现。在我们的实验中,将CoVe提供给这些新网络总是能够提高其性能,所以我们很高兴发布生成CoVe的已训练网络,以便于进一步探索NLP中的可重用表征。
词向量
可以说今天的大多数用于NLP的深度学习模式主要是依靠用词向量来表征单个单词的含义。而对于那些不熟悉这个概念的人来说,所有这一切只不过意味着我们将语言中的每个单词与一个称为向量的数字列表相关联在一起。

图1:在深度学习中,常常将单词表征为向量。深度学习模型不是像读文本般读取序列单词,而是读取单词向量的序列。
预训练词向量
有时,在为特定任务训练模型之前,常常将词向量初始化为随机数列表,但是用诸如word2vec、GloVe或FastText之类的方法来初始化模型的词向量也是很常见的。这些方法中的每一种都定义了一种学习具有有用属性的词向量的方法。前两种假说认为,至少有一部分单词的含义与它的用法是相关的。
word2vec通过训练一个模型来处理一个单词并预测一个本地情境窗口;模型看到一个单词,并试图预测在其周围的单词。
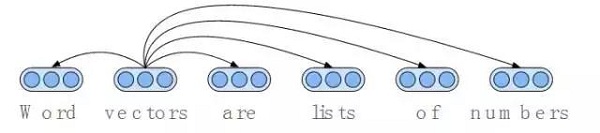
图2:像word2vec和GloVe这样的算法产生的词向量与在自然语言中经常出现的词向量是相关的。这样一来,“(vector)向量”的向量意味着出现在诸如“lists”、“of”以及“numbers”这类单词周围的单词“vector”。
GloVe采取类似的方法,但它还明确地添加了关于每个单词与其他每个单词发生频率的统计信息。在这两种情况下,每个单词都由相应的词向量表示,并且训练强制词向量以与自然语言中单词的使用相关联的方式相互关联。
预训词向量的突现属性
如果将这些词向量视为空间中的点,我们可以从中看到一种令人着迷的紧密关系,从而让人联想到单词之间的语义关系。
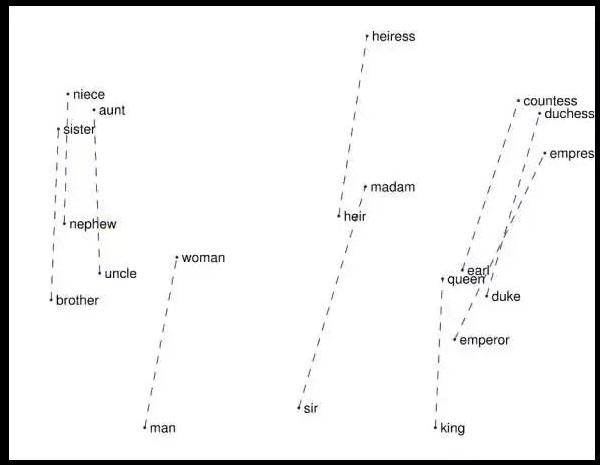
图3:捕获到的男性—女性单词对之间的向量差异(Pennington等人在2014提出的观点)。
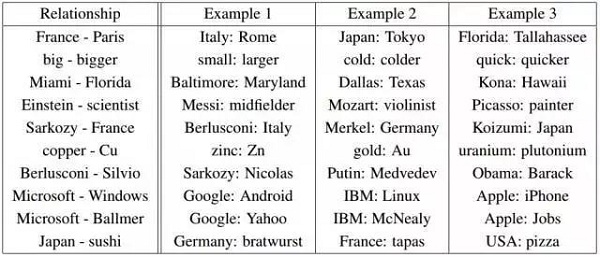
图4:对于关系a-b,c:d表示c +(a-b)产生更接近d的向量(Mikolov等人于2013年提出观点)。
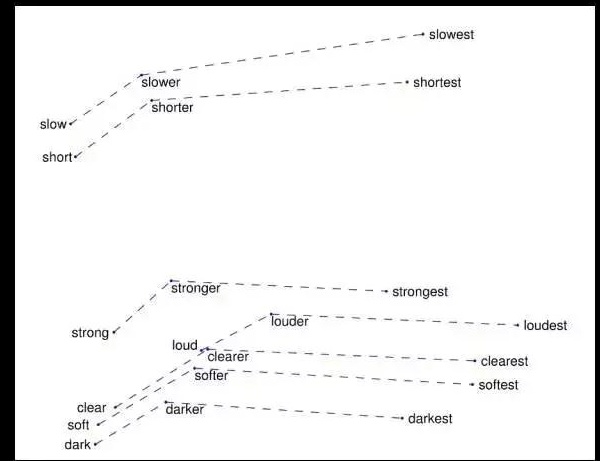
图5:捕获到的比较和较高级关系之间的向量差异(Pennington等人于2014提出的观点)。
很快就发现,在为目标任务初始化一个模型时,如果用word2vec或GloVe所定义的用于中级任务的预训练词向量进行训练,将会使模型在目标任务上更加具有优势。因此,由word2vec和GloVe生成的词向量在NLP的许多任务中找到了广泛的实验方法。
隐藏向量
这些预训练的词向量表现出有趣的属性,并提供了对随机初始化的词矢量的性能增益。但是正如上面所叙述的那样,单词很少独立出现。使用预训练词向量的模型必须学习如何使用它们。我们的工作是通过对中级任务进行训练,找到一种用于改进词向量情境化的随机初始化方法,从而提取词矢量。
编码器
情境化词向量的一种常见方法是使用一个循环神经网络(RNN)。RNN是一种处理可变长度的向量序列的深度学习模型。这使得它们适合于处理词向量的序列。我们使用的是一种称为长短期记忆网络(LSTM)的特定类型的RNN,从而更好地处理长序列。在处理的每个步骤中,LSTM接收一个词向量,并输出一个称为隐藏向量的新向量。该过程通常被称为编码序列,并且将执行编码的神经网络称为编码器。
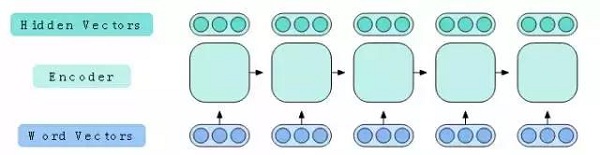
图6:LSTM编码器接收一个词矢量序列并输出一个隐藏向量序列。
双向编码器
这些隐藏的向量不包含序列中稍后出现的单词的信息,但这一点很容易进行补救。我们可以反向运行一个LSTM从而获得一些反向输出向量,并且我们可以将它们与正向LSTM的输出向量相连,以获得更有用的隐藏向量。我们把这对正向和反向的LSTM当做一个单元,它通常被称为双向LSTM。它接收一个词向量序列,运行正向和反向LSTM,连接对应于相同输入的输出,并返回所得到的隐藏向量的结果序列。
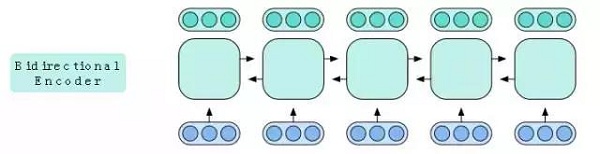
图7:双向编码器包含每个单词前后的信息。
我们使用一组两个双向LSTM作为编码器。第一个双向LSTM处理其整个序列,然后将输出传递给第二个。
机器翻译中的隐藏向量
正如预训练的词向量被证明是许多NLP任务的有效表征一样,我们期望预训练我们的编码器,以便它能够输出通用的隐藏向量。为此,我们选择机器翻译作为第一个训练任务。机器翻译训练集要远大于其他大多数NLP任务的翻译训练集,翻译任务的性质似乎具有一种吸引人的属性,可用于训练通用情境编码器,例如,翻译似乎比文本分类这样的任务需要更一般的语言理解能力。
解码器
在实验中,我们教编码器如何如何将英语句子翻译成德语句子,从而教它生成有用的隐藏向量。编码器为英语句子生成隐藏向量,另一个称为解码器的神经网络在生成德语句子时将引用这些隐藏向量。
正如LSTM是我们编码器的主干一样,LSTM在解码器中也扮演着重要的角色。我们使用一个与编码器一样具有两个层的解码器LSTM。解码器LSTM从编码器的状态初始化,读入一个特殊的德语词向量作为开始,并生成一个解码器状态向量。
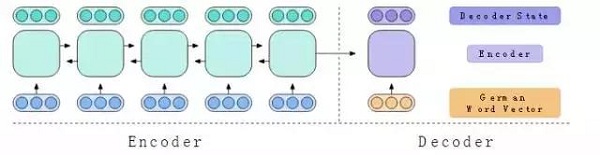
图8:解码器使用单向LSTM从输入词向量中创建解码器状态。
注意
注意机制回顾隐藏向量,以便决定接下来要翻译英文句子的哪一部分。它使用状态向量来确定每个隐藏向量的重要性,然后它生成一个新的向量,我们称之为情境调整状态(context-adjusted state)来记录其观察结果。
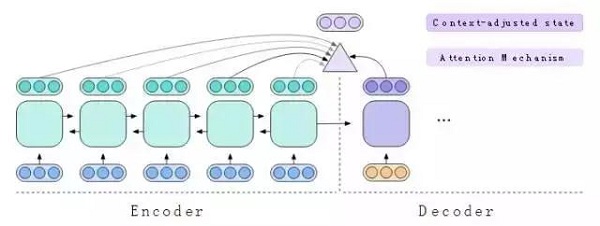
图9:注意机制使用隐藏状态和解码器状态来生成情境调整状态。
生成
生成器稍后将查看情境调整状态以确定要输出的德语单词,并且将情境调整状态传递回解码器,从而使其对已经翻译的内容与足够准确的理解。解码器重复此过程,直到完成翻译。这是一种标准的注意编码—解码器体系结构,用于学习序列的序列任务,如机器翻译。
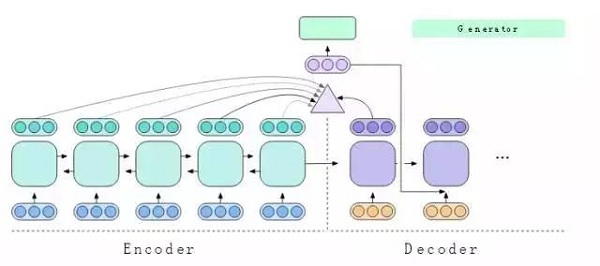
图10:生成器使用情境调整状态来选择输出单词。
来自预训练MT-LSTM的情境向量
当训练完成后,我们可以提取已训练的LSTM作为机器翻译的编码器。我们将这个已预训练的LSTM称为MT-LSTM,并使用它来输出用于新句子的隐藏向量。当使用这些机器翻译隐藏向量作为另一个NLP模型的输入时,我们将它们称为情境向量(CoVe)。
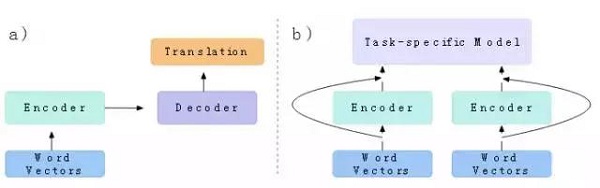
图11:a)编码器的训练b)将其重新用作新模型的一部分
用CoVe进行实验
我们的实验探索了使用预训练的MT-LSTM生成用于文本分类和问答模型的CoVe的优点,但CoVe可以与任何表征其输入的模型一起作为向量序列。
分类
我们研究两种不同类型的文本分类任务。第一种,包括情绪分析和问题分类,具有单一的输入。第二种仅包括蕴涵分类(entailment classification),有两个输入。对于这两种,我们使用双集中分类网络(Biattentive Classification Network)。如果只有一个输入,我们将其复制,假装有两个,让模型知道避免运行冗余计算。而且我们不需要了解BCN理解CoVe的细节以及使用它们的好处。
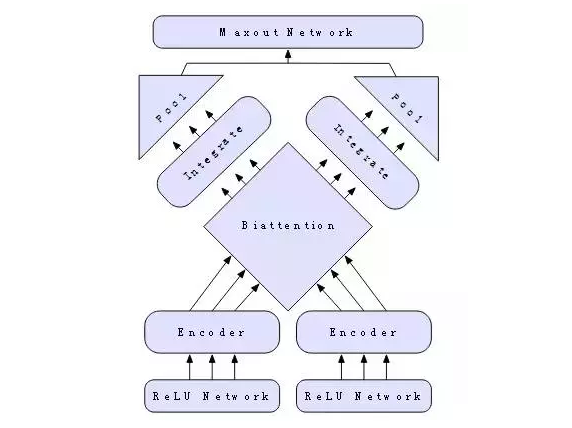
图12:一个双集中分类网络。
问答
我们依靠动态关注网络(Dynamic Coattention Network)进行问答实验。为了分析MT数据集对模型学习其他任务性能的影响,我们使用一个稍微修改过的DCN,但实验测试了整个CoVe和CoVe与字符向量的总体有效性,我们使用udpated DCN +。
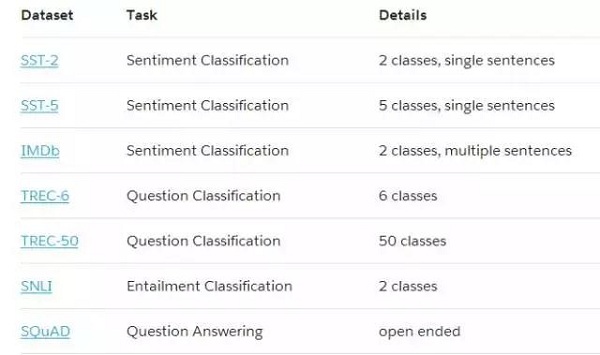
表1:我们实验中数据集和任务的总结。
GloVe+CoVe
对于每个任务,我们用不同的方式来表征输入序列。我们可以将每个序列表示为我们训练的随机初始化的词向量序列,我们可以使用GloVe,或者我们可以将GloVe和CoVe一起使用。 在后一种情况下,我们采用GloVe序列,通过预训练的MT-LSTM运行它,以获得CoVe序列,并且我们将CoVe序列中的每个向量与GloVe序列中的相应向量相加。不管是MT-LSTM还是GloVe都不是作为分类或问答模型的一部分进行训练的。
实验结果表明,在随机初始化词向量和单独使用GloVe的情况下,包括CoVe以及GloVe在内总是能够提高其性能。
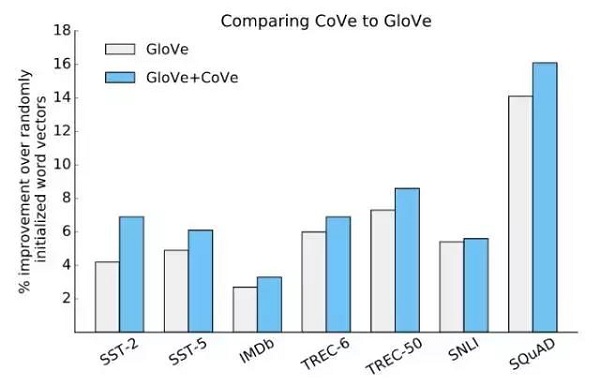
图13:通过使用GloVe和添加CoVe来验证性能是否提高。
更多MT→更好CoVe
改变用于训练MT-LSTM的数据量表明,用更大的数据集进行训练会导致更高质量的MT-LSTM,在这种情况下,更高的质量意味着使用它来生成CoVe会在分类和问题应答任务上产生更好的性能。
结果表明,用较少的MT训练数据训练的MT-lstms所获得的增益是不显著的,在某些情况下,使用这些小MT数据集训练MT-lstm产量,实际上会损害性能。这可能表明使用CoVe的好处来自于使用不平凡的MT-lstm。这也可能表明,MT训练集的领域对产生的MT-lstm所提供的任务有影响。
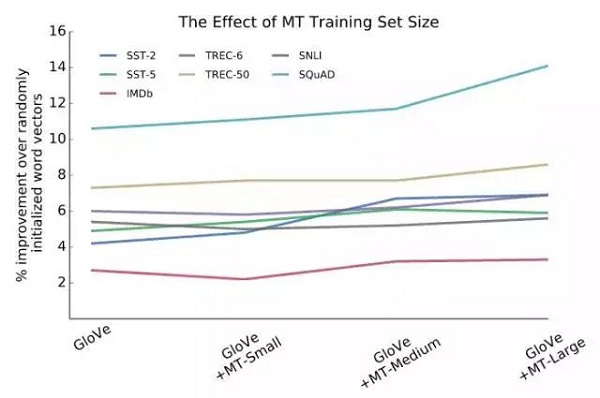
图14:MT-LSTM的训练集大小对使用CoVe的模型的验证性能有明显的影响。在这里,MT-Small是2016年WMT多模态数据集,MT-Medium是2016年IWSLT训练集,MT-Large是2017年WMT新闻追踪训练集。
CoVe和字符
在这些实验中,我们尝试向GloVe和CoVe添加字符向量。结果表明,在某些任务中,字符向量可以与GloVe和CoVe一起工作,以获得更高的性能。这表明CoVe添加了与字符和单词级信息相辅相成的信息。
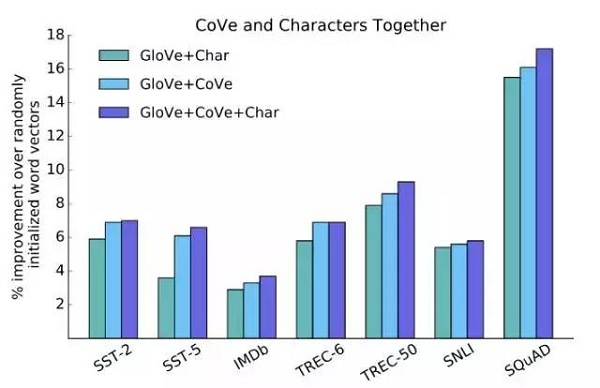
图15:CoVe与字符向量中存储的字符级信息互补。
测试性能
我们所有好的模型都使用了GloVe、CoVe和字符向量。我们采用了为每个任务实现更高验证性能的模型,并在测试集上对这些模型进行了测试。上图显示,相较于我们在出发点的表现,添加CoVe始终可以提升我们的模型性能,下表显示,在我们七个任务中的其中三个里面,在测试集层面,足以推动我们的起始模式向艺术表现的新状态发展。

表2:在测试时,测试性能与其他机器学习方法的比较(7/12/17)。
值得注意的是,就像我们使用机器翻译数据来改进我们的模型一样,sst-2和IMDb的先进的模型也在使用监督训练集之外的数据。对于sst-2来说,模型使用了8200万未标记的Amazon评论,而IMDb的模型使用了50000个未标记的IMDb评论,此外还有22500个监督训练样本。这两种方法都增加了与目标任务相似的数据,而不是我们使用的机器翻译数据集。这些模型的优越性可能突出显示了附加数据的种类与附加数据的有益程度之间的联系。
结论
我们展示了如何训练一个神经网络,使其能够学习情境中单词的表征,并且我们展示了我们可以使用该网络的一部分——MT-LSTM,从而帮助网络学习NLP中的其他任务。在分类和问答模型中,MT-LSTM提供的情境向量或CoVe都无疑推动它们达到更好的性能。我们用于训练MT-LSTM的数据越多,改进越明显,这似乎与使用其他形式的预先训练向量表征所带来的改进相辅相成。通过将来自GloVe,CoVe和字符向量的信息相结合,我们能够在各种NLP任务中提高基准模型的性能。